This guide offers a list of 50+ most asked data science interview questions and answers for freshers and experienced professionals. You will also find an interview cheat sheet and helpful tips to prepare for data science interviews.
But before we move on to the frequently asked data science interview questions, let’s cover the basics.
| Category | Details |
|---|---|
| Total Duration | 2–4 weeks (from application to final offer) |
| Number of Rounds | 3 to 6 rounds (varies by company) |
| Types of Rounds | – Resume Screening – Online Test (Coding/MCQs) – Technical Interview(s) – Case Study or Project Discussion – HR/Behavioral Interview |
| Question Types | – Python & SQL Coding – Statistics & Probability – Machine Learning – Business Scenarios – Communication Skills |
| Difficulty Level | Medium to High (varies by role and company) |
| Each Round Duration | 30–90 minutes |
| Top Hiring Companies | Google, Amazon, Flipkart, TCS, Microsoft, Accenture, Capgemini |
| Most Common Tools Asked | Python, Pandas, NumPy, SQL, Scikit-learn, Excel, Tableau, Jupyter |
| Preparation Time Needed | 2–3 weeks of focused preparation recommended |
So, what is data science?
Data = Information
Science = Way of understanding things
Data Science = A smart way to understand information and find answers using it.
Data Science definition
Data science is the field of using data, statistics, and programming to solve real-world problems. It helps businesses make smarter decisions and predict future outcomes.
History and origin
The roots of data science go back to the 1960s, but the term gained real popularity in the early 2000s. William S. Cleveland is one of the key figures who helped shape it into a modern discipline.
Are data science jobs in high demand?
Today, data science is one of the most in-demand fields in the world. According to the Bureau of Labor Statistics, data science jobs are expected to grow by 36% between 2023 and 2033.
An estimated 20,800 data scientist job openings are projected each year on average.
From healthcare to finance, every industry needs skilled data professionals. Common job titles include –
- Data analyst
- Data scientist
- Machine learning engineer
- AI specialist
If you are applying for any of these roles, here are some of the most commonly asked data science interview questions to help you prepare.
Note:
We have categorized the questions into six key sections – most asked, for freshers, for experienced professionals, technical (advanced), coding, and questions asked by top IT companies. This structure will help you focus on the areas that matter most for your interview preparation.
Also Read - Top 35+ Data Analyst Interview Questions and Answers
Most Asked Data Science Interview Questions
Here are some of the top data scientist interview questions and answers. These are the 10 most asked questions. Go through them to understand what interviewers expect.
- What is the distinction between supervised and unsupervised learning?
In supervised learning, models train on labeled data. You know the correct output.
In unsupervised learning, the data has no labels. The model finds patterns on its own.
| Type | Input Data | Goal | Examples |
| Supervised | Labeled | Prediction | Regression, Classification |
| Unsupervised | Unlabeled | Pattern Detection | Clustering, PCA |
- Describe how you would build a decision tree from scratch.
Start by selecting the best feature using Gini index or information gain.
Split data based on feature values. Repeat the process on child nodes.
Stop when nodes are pure or other stopping criteria are met.
- Explain bias versus variance and how you would balance them.
Bias is error from incorrect assumptions. Variance is error from sensitivity to data. Too much bias causes underfitting. High variance causes overfitting.
To balance them, I choose simpler models first, then tune complexity using cross-validation.
- How do you treat data with over 30% missing values?
If the dataset is large, I remove the affected rows. If small, I use imputation – mean, mode, or even predictive models.
The method depends on the nature of the data and business need.
- What are your methods for preventing overfitting?
I use cross-validation, early stopping, and regularization (like L1 or L2).
Simpler models also help. If needed, I increase data size through augmentation.
- Walk me through the steps of deploying and maintaining a model.
First, I prepare a pipeline for training and prediction. After deployment, I monitor accuracy and retrain as needed. I also track concept drift and update data pipelines regularly.
- How would you design an A/B test and interpret its outcome?
I divide users randomly into two groups. One sees the current version (A), the other sees the new version (B).
I track metrics like conversion rate and run a statistical test (e.g., t-test) to compare them.
If the p-value is < 0.05, I consider the difference significant.
- Explain the ROC curve and AUC metric.
ROC curve plots True Positive Rate vs False Positive Rate.
AUC is the area under this curve.
AUC near 1.0 shows great performance. AUC near 0.5 means the model is guessing.
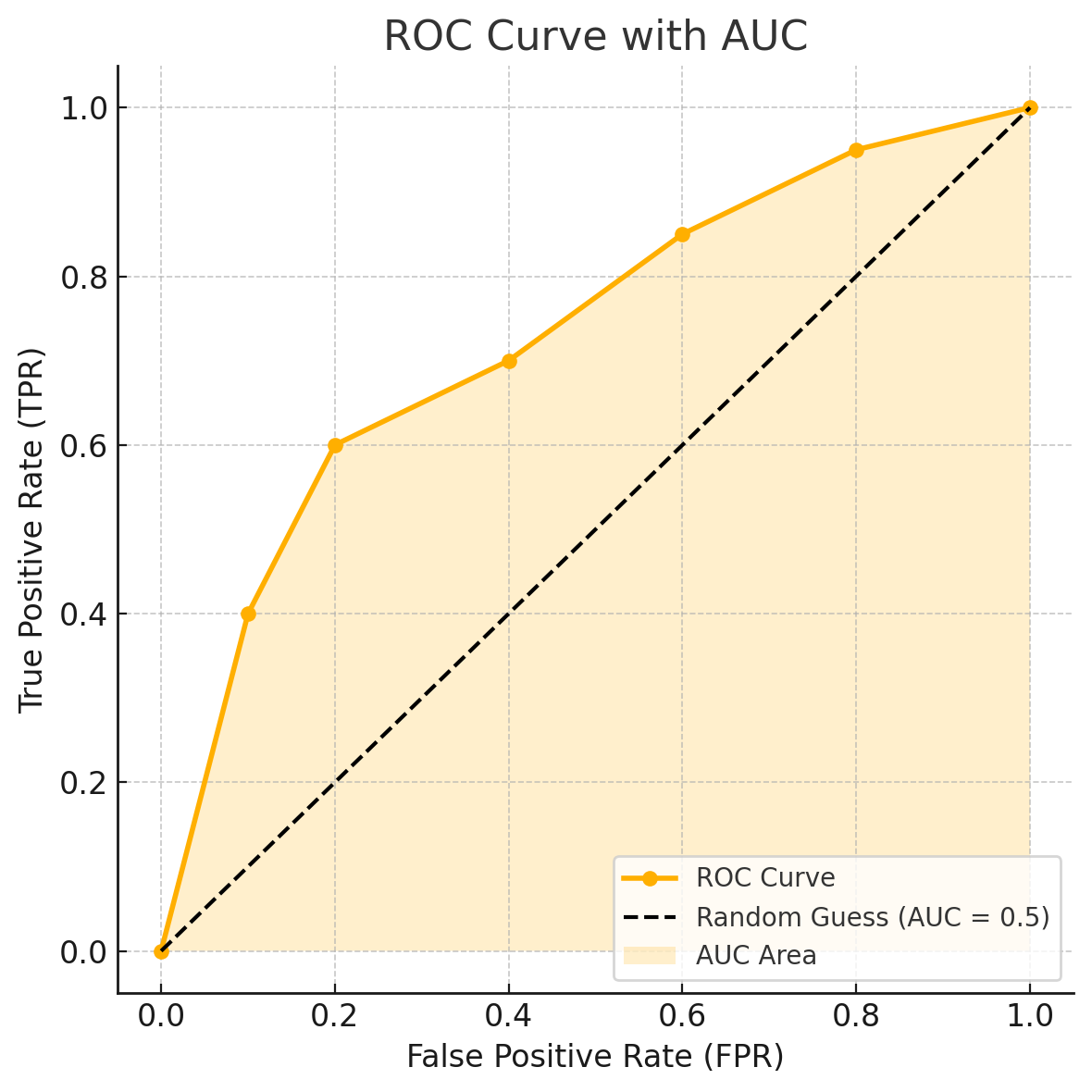
- How do you evaluate a clustering model without ground truth?
I use internal metrics like Silhouette score, Davies-Bouldin index, or inertia. These don’t require true labels and still tell how well clusters are formed.
- When and why would you use dimensionality reduction?
I use it when there are too many features. Too many dimensions can confuse the model or slow it down. PCA or t-SNE helps simplify the data while keeping useful information.
Data Science Interview Questions for Freshers
If you are a fresher or a recent graduate, these interview questions for a data scientist will help you get started.
- What is Data Science?
Data science is the field of using data to solve problems. It combines statistics, programming, and domain knowledge to extract insights, make predictions, and support decisions.
- What is the difference between data analytics and data science?
Data analytics focuses on examining past data to find patterns and trends. Data science goes further – it also builds predictive models and uses machine learning to forecast future outcomes or automate decisions.
- What is SQL and why is it used in data science?
SQL stands for Structured Query Language. It is used to read and work with data in relational databases.
In data science, SQL helps extract, filter, and join data before analysis.
Without clean data, no model works well. So SQL is essential.
- Name three key statistics: define and contrast them.
| Term | Definition | Purpose |
| Mean | Average of numbers | Measures central tendency |
| Median | Middle value in sorted list | Handles skewed data better |
| Mode | Most frequent value | Useful for categories |
Mean is sensitive to outliers. Median is more stable. Mode works for categorical features.
- What is the role of a primary key?
A primary key uniquely identifies each record in a table.
It cannot be null or duplicate. It helps avoid data duplication.
- How do you use GROUP BY versus WHERE?
WHERE filters rows before grouping. GROUP BY groups rows to apply functions like SUM() or COUNT().
Example:
SELECT city, COUNT(*) FROM customers
WHERE status = ‘active’
GROUP BY city;
- What is logistic regression?
It is a model used to predict binary outcomes. It outputs probabilities using the sigmoid function.
For example, will a user click or not?
The image below shows the sigmoid curve, which maps input values to probabilities between 0 and 1. The curve has an S-shape and is steepest around zero – this is where small changes in input can flip predictions.
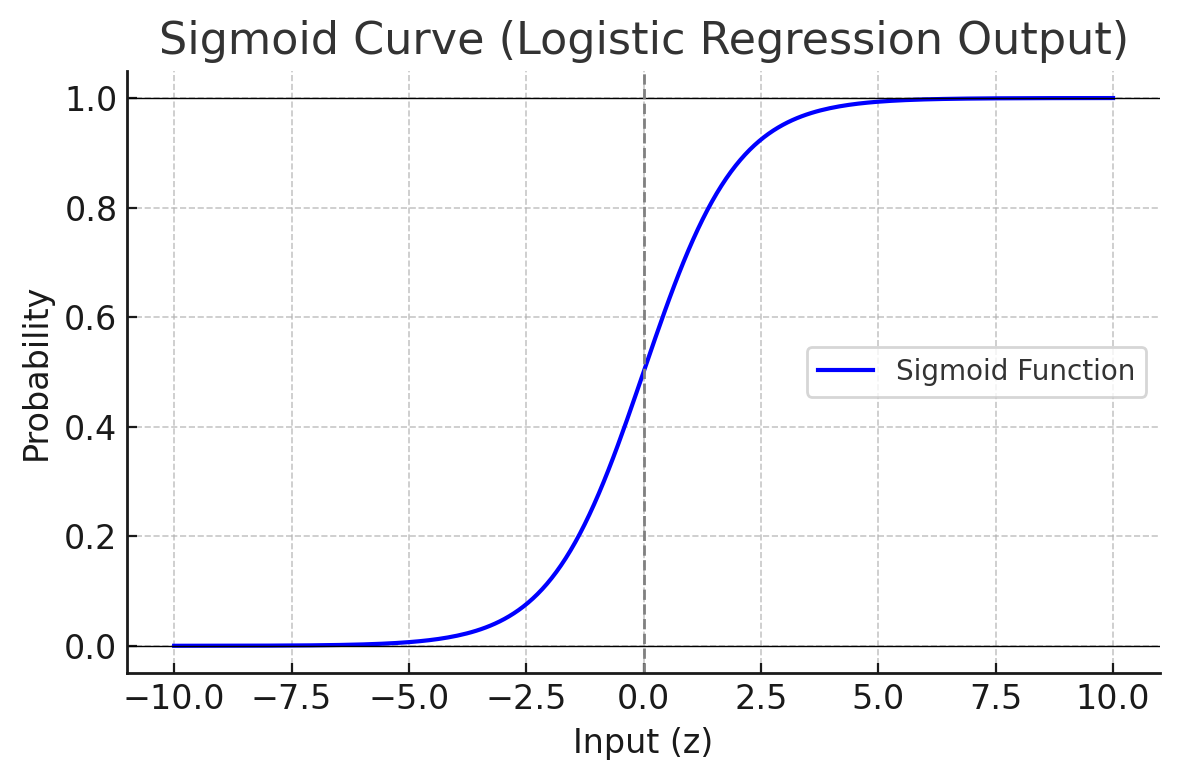
- Describe K-means clustering steps.
- Choose K cluster centers randomly
- Assign data points to nearest cluster
- Update centers based on current members
- Repeat until centers stop moving
- What is the difference between mean and median?
Mean adds all values and divides by count. Median is the middle value when sorted. In skewed data, median is often more reliable.
Note – Interview questions for data science fresher roles often include basic concepts, Python, statistics, and real-life problem-solving scenarios.
Also Read - Top 25+ SQL DBA Interview Questions and Answers
Data Science Interview Questions for Experienced Professionals
These interview questions in data science are often asked during technical rounds for experienced roles.
- How have you handled a large messy dataset in past projects?
I once worked with millions of user logs from an e-commerce platform. The data had nulls, mixed formats, and duplicate rows. I wrote preprocessing scripts in Python using Pandas and Dask for faster performance. I validated entries using regex and business rules. Outliers were flagged separately for review.
- Explain a time you communicated technical findings to a business audience.
In one project, we found that customer churn was strongly linked to delivery delays. Instead of showing model weights, I used visuals like bar charts and simple bullet points. I compared high-risk vs. low-risk customer behavior. This helped the operations team take action fast.
- Describe a model that went off-track – what did you do?
A fraud detection model showed a sudden drop in precision.
On inspection, I noticed a change in transaction patterns due to a festival campaign.
I retrained the model with recent data and added time-based features. It recovered within two weeks of deployment.
- How do you incorporate stakeholder feedback into model design?
During development, I run check-ins with product and business teams.
They share what decisions depend on the model.
For example, one team wanted the model to flag risk even at lower probability. So, I adjusted the decision threshold and retrained it on more negative samples.
- Share an experience where you improved a model’s performance.
In a marketing campaign model, recall was low. I added features from email interaction history and used SMOTE to balance the dataset. I also tuned hyperparameters using GridSearchCV. The model’s F1 score went up by 18%.
- What’s the most important metric you tracked in production, and why?
| Metric | Why It Matters |
| F1 Score | Balances precision and recall |
| Latency | Affects real-time prediction speed |
| Drift Score | Detects change in incoming data |
For most cases, I track F1 score and drift score together. They help keep performance stable over time.
Data Science Technical Interview Questions (Advanced)
Here are advanced data scientist interview questions that test your technical expertise and real-world problem-solving skills.
- What are the assumptions behind linear regression?
Linear regression is based on five key assumptions:
| Assumption | Description |
| Linearity | Relationship between input and output is linear |
| Independence | Errors are not related across observations |
| Homoscedasticity | Constant variance in residuals |
| Normality | Residuals are normally distributed |
| No multicollinearity | Features are not strongly correlated |
Violating these affects the model’s reliability.
- Explain how backpropagation works in a neural network.
Backpropagation updates weights in a neural network by calculating gradients of the loss function. It uses the chain rule to move errors backward from the output layer. Each layer’s weights are adjusted to reduce the final error.
- Describe the difference between bagging and boosting.
Both are ensemble methods, but they work differently.
| Feature | Bagging | Boosting |
| Training | Parallel | Sequential |
| Goal | Reduce variance | Reduce bias |
| Example | Random Forest | XGBoost, AdaBoost |
Bagging trains models independently. Boosting learns from previous mistakes.
- How do you detect heteroscedasticity in regression?
I plot residuals vs predicted values. If the spread increases or forms a pattern, variance is not constant. Breusch-Pagan test can also be used to confirm this.
- Walk through how to evaluate ARIMA model components.
ARIMA has three parts: AR (p), I (d), MA (q).
I use ACF and PACF plots to choose p and q.
d refers to the number of times the series must be differenced to become stationary.
Data Science Coding Interview Questions
Now let’s look at some coding-focused interview questions for a data scientist, including Python, SQL, and algorithms.
- Write a Python function to compute a confidence interval.
import scipy.stats as stats
import numpy as np
def confidence_interval(data, confidence=0.95):
n = len(data)
mean = np.mean(data)
std_err = stats.sem(data)
margin = std_err * stats.t.ppf((1 + confidence) / 2, n – 1)
return (mean – margin, mean + margin)
Use this when you have a sample and want to estimate the true mean.
- Using SQL, how would you find the median of a numeric column?
SELECT AVG(salary) AS median_salary
FROM (
SELECT salary,
ROW_NUMBER() OVER (ORDER BY salary) AS rn,
COUNT(*) OVER () AS total
FROM employees
) sub
WHERE rn IN (FLOOR((total + 1) / 2), CEIL((total + 1) / 2));
Works in most SQL dialects with window functions.
- Given Python lists A and B, write code to find items present in both.
A = [1, 2, 3, 4]
B = [3, 4, 5, 6]
common = list(set(A) & set(B))
print(common) # Output: [3, 4]
Simple and fast using set intersection.
- Write a function to sum odd-indexed elements in a list.
def sum_odd_indexed(lst):
return sum(lst[i] for i in range(1, len(lst), 2))
# Example
print(sum_odd_indexed([10, 20, 30, 40])) # Output: 60 (20 + 40)
Data Science MCQs
- What does the sigmoid function output in logistic regression?
A. Any real number
B. Only 0 or 1
C. A value between 0 and 1
D. A binary class label
Answer: C. A value between 0 and 1
- Which SQL clause is used to group records with the same values?
A. WHERE
B. ORDER BY
C. GROUP BY
D. HAVING
Answer: C. GROUP BY
- Which metric is best when classes are imbalanced?
A. Accuracy
B. Recall
C. F1 Score
D. Mean Squared Error
Answer: C. F1 Score
- In Python, which library is used for handling labeled datasets?
A. NumPy
B. Pandas
C. Matplotlib
D. TensorFlow
Answer: B. Pandas
- What does p-value < 0.05 generally indicate in hypothesis testing?
A. Weak correlation
B. Strong probability
C. Statistically significant result
D. Model overfitting
Answer: C. Statistically significant result
- What is the role of a primary key in SQL?
A. Creates foreign tables
B. Sorts the data
C. Identifies unique records
D. Deletes null values
Answer: C. Identifies unique records
Other Important Data Science Interview Questions
This section covers additional interview questions in data science that often appear across various company rounds.
Statistics Interview Questions for Data Scientists
Here are key data scientist questions based on statistics that are commonly asked during interviews.
- Define Type I and Type II errors.
- How is a p-value different from confidence interval?
- What are z-test, t-test, and F-test used for?
- What is a chi-squared distribution applied to?
- How do you detect and correct skewness in data?
Data Scientist Python Interview Questions
- How would you calculate Euclidean distance between two vectors?
- Show code to draw N samples from a normal distribution and plot histogram.
- Write a function to compute rolling averages on a list of numbers.
- How do you manipulate missing values using pandas?
- Demonstrate one-hot encoding for categorical data in Python.
Data Science and Machine Learning Interview Questions
- Compare decision trees and random forests.
- What is the kernel trick in SVMs and when do you use it?
- Explain gradient descent vs. stochastic gradient descent.
- What is the difference between discriminative and generative models?
- Describe transfer learning and its main benefit.
Also Read - Top 75+ Python Interview Questions and Answers
Data Science Interview Questions Asked by Top IT Companies
These are some of the most commonly asked data science questions in interviews at top tech companies.
Google Data Scientist Interview Questions
- How would you predict user engagement for a new feature?
- What is the difference between boosting and bagging?
- Explain the mechanics of a neural network and activation functions.
- Describe a time you handled ambiguity in data with limited visibility.
Microsoft Data Scientist Interview Questions
Here’s what to expect in a typical Microsoft data science interview, including key topics and question patterns.
- What assumptions underlie linear regression?
- How do you choose the number of clusters in K-means?
- Write code for evaluating time-series stationarity.
- Explain handling unbalanced datasets with ensemble models.
Apple Data Science Interview Questions
Here are some common topics and question types asked in an Apple data science interview.
- How would you build a recommendation engine for the App Store?
- What metrics would you track post-release for model health monitoring?
- Write a SQL query to find users with anomalous usage patterns.
- Describe a time you simplified a complex model for stakeholders.
Amazon Data Scientist Interview Questions
- Design and evaluate an A/B test for Prime display strategies.
- Explain how you’d forecast demand using historical sales data.
- What’s your approach to feature selection at scale?
- How do you detect concept drift post-deployment?
Accenture Data Science Interview Questions
Here are commonly asked questions from a typical Accenture data scientist interview to help you prepare.
- Explain a data pipeline you’ve built end-to-end.
- Describe a time when you optimized a machine learning model.
- Write SQL to detect duplicate transactions.
- How do you validate model results with business data?
Capgemini Data Scientist Interview Questions
- How do you cleanse and normalize data in ETL processes?
- Describe how you’d approach missing data imputation.
- Write code to convert categorical features into numeric.
- How do you track and document data lineage?
IBM Data Science Interview Questions
- How would you deploy a model using IBM Cloud/Azure?
- Explain the process of hyperparameter tuning.
- Write code to evaluate a classifier’s F1 score.
- Tell me about a time you refactored code for better performance.
TCS Data Scientist Interview Questions
These are commonly asked questions in a typical TCS data scientist interview, based on recent candidate experiences.
- How do you integrate RDBMS and NoSQL data sources?
- Explain designing a star schema in data warehousing.
- Write a script to detect and flag outliers in Python.
- Describe handling high-dimensional financial data.
Wipro Data Scientist Interview Questions
- How would you forecast quarterly business KPIs?
- Explain anomaly detection in streaming sensor data.
- Write SQL to compute month-over-month growth.
- How do you monitor model drift in production?
Cognizant Data Scientist Interview Questions
- How do you profile and understand new datasets?
- What steps do you take to scale a model for large data?
- Write Python code to merge and aggregate datasets.
- Tell me about a data solution you implemented in production.
JP Morgan Data Scientist Interview Questions
- How do you model financial time-series volatility?
- Explain risk prediction using logistic regression.
- Write code to backtest a trading model.
- How do you handle multivariate dependencies in finance?
NVIDIA Data Scientist Interview Questions
- How would you build a computer vision model for defect detection?
- Explain feature engineering for sensor data from GPUs.
- Write code to evaluate model latency and throughput.
- How do you manage model deployment on edge devices?
Citibank Data Scientist Interview Questions
- How would you detect fraudulent transaction patterns?
- Explain credit scoring model development process.
- Write SQL to identify high-risk customer segments.
- Describe improving existing risk models with new data.
Intuit Data Scientist Interview Questions
- How would you forecast user activity over tax seasons?
- Explain handling highly seasonal revenue data.
- Write code to bucket customers by usage patterns.
- How would you evaluate model fairness and bias?
L&T Data Scientist Interview Questions
- How would you model predictive maintenance for machinery?
- Explain time-series forecasting for equipment failure.
- How do you integrate sensor and enterprise data?
- Describe optimizing sensor-based anomaly alerts.
Flipkart Data Science Interview Questions
- How would you recommend products to first-time users?
- Explain metrics to evaluate recommendation performance.
- Write code to label sessions as likely conversion vs bounce.
- Describe a model you scaled for high-traffic shopping events.
Walmart Data Scientist Interview Questions
- How would you forecast demand across multiple stores?
- Explain inventory optimization using clustering.
- Write SQL to find underperforming SKUs by region.
- How do you detect sales anomalies in real-time?
Data Science Interview Questions Cheat Sheet
If you are short on prep time, this quick data scientist interview cheat sheet covers the must-know topics in under 2 minutes.
| Topic | Quick Recall Point |
|---|---|
| Supervised vs Unsupervised | Labeled vs unlabeled data. Used in prediction vs grouping tasks. |
| Overfitting | Model fits training data too closely. Use cross-validation, pruning, or regularization. |
| Bias vs Variance | Bias = error from assumptions. Variance = error from sensitivity to data. Balance both. |
| ROC & AUC | ROC plots TPR vs FPR. AUC shows model’s ability to classify — closer to 1 is better. |
| Logistic Regression | For binary output. Uses sigmoid function to return probabilities. |
| SQL GROUP BY vs WHERE | WHERE filters rows; GROUP BY aggregates them. |
| p, d, q in ARIMA | p = past values, d = differencing, q = error terms. |
| Feature Scaling | Use MinMaxScaler or StandardScaler before distance-based models. |
| Confusion Matrix | Shows TP, FP, TN, FN. Use it to derive precision and recall. |
| Clustering Evaluation | Use Silhouette Score. Closer to 1 means better-defined clusters. |
| Cross-Validation | Splits data into k folds to test model robustness. |
| Gradient Descent | Optimizer that updates weights to reduce loss. |
| Mean vs Median | Mean is sensitive to outliers. Median is not. |
| Primary Key | Uniquely identifies rows in a table. |
| Feature Selection | Pick top features using correlation, mutual info, or tree importance. |
| A/B Testing | Randomly split users. Compare two versions using metrics like conversion rate. |
| Dimensionality Reduction | Use PCA or t-SNE to reduce features without losing too much info. |
| Python Libraries | Pandas, NumPy, Scikit-learn, Matplotlib, Seaborn. |
| Statistics Must-Know | Mean, Median, Mode, Std Dev, P-value, Confidence Interval. |
| NLP Basics | Tokenization, stemming, TF-IDF, stopwords removal, word embeddings. |
Pro Tips for Data Scientist Interview Preparation
Here are some practical tips to help with your data scientist interview preparation – beyond just revising theory and practicing code.
- Skim recent company blog posts to understand their data culture
- Practice explaining ML concepts like you’re talking to a non-tech friend
- Prepare 2–3 failure stories and what you learned
- Review your GitHub or portfolio projects – they may ask about them
- Rehearse writing clean code on a whiteboard or notepad
Wrapping Up
These 50+ data science interview questions cover everything from basics to advanced topics. Review them well, practice your answers, and follow the tips we have shared.
Looking for your next big opportunity?
Hirist is an online job portal for IT professionals. Find the best Data Science jobs in India right here.
Also Read - How to Become a Data Scientist in 2026?
FAQs
According to AmbitionBox, data scientists in India with 1–8 years of experience earn between ₹4 Lakhs to ₹29.2 Lakhs annually. The average salary is around ₹15.4 Lakhs per year.
A data science interview experience usually includes multiple rounds – starting with resume screening, followed by coding tests, case studies, and technical + behavioral interviews. You may also be asked to walk through a past project.
You will get a mix of:
Python/SQL coding
Statistics and ML concepts
Scenario-based problem solving
Business understanding
Questions from your past work
These are often oral, quick-fire questions asked in academic or fresher-level interviews to test basic understanding.
What is the difference between classification and regression?
Explain the curse of dimensionality in simple terms.
What is a p-value, and why is it important?
Name different types of sampling techniques.
When is mean a bad measure of central tendency?
These focus on conceptual clarity, enthusiasm for learning, and basic coding or project experience.
How would you explain data science to a non-technical person?
What tools have you used for data analysis in your projects?
How do you handle missing data in a dataset?
Write a SQL query to find the second-highest salary from a table.
What’s the difference between inner join and left join?
These revolve around how data scientists use AWS services for storage, computation, and model deployment.
Which AWS service would you use for large-scale data storage?
How do you deploy a trained model using AWS SageMaker?
What is the difference between S3 and EBS?
How do you set up auto-scaling for a model API on AWS?
How would you secure data pipelines on AWS using IAM roles?

{kind=link}