AWS Glue is a cloud-based ETL (extract, transform, load) service launched by Amazon Web Services in 2017. It was introduced to simplify the way businesses handle big data without managing servers or complex infrastructure. Founded under the vision of Jeff Bezos and the AWS team, Glue quickly became a go-to tool for data engineers and analysts. It automates tasks like data preparation, transformation, and cataloging, making it useful for roles such as data engineers, ETL developers, and cloud architects. To help you prepare, here are the most asked AWS Glue interview questions with clear answers.
Fun Fact: According to Enlyft, over 6,117 companies are using AWS Glue today.
AWS Glue Interview Basics

AWS Glue Interview Questions for Freshers
Here are some of the most common AWS Glue interview questions and answers that beginners should know before stepping into an interview.
- What is AWS Glue and what is it used for?
AWS Glue is a serverless data integration service from Amazon Web Services. It automates the process of extracting, transforming, and loading (ETL) data for analytics, reporting, and machine learning. With features like crawlers, job scheduling, the Data Catalog, and streaming ETL for real-time data pipelines, it helps organize and process data efficiently across multiple sources.
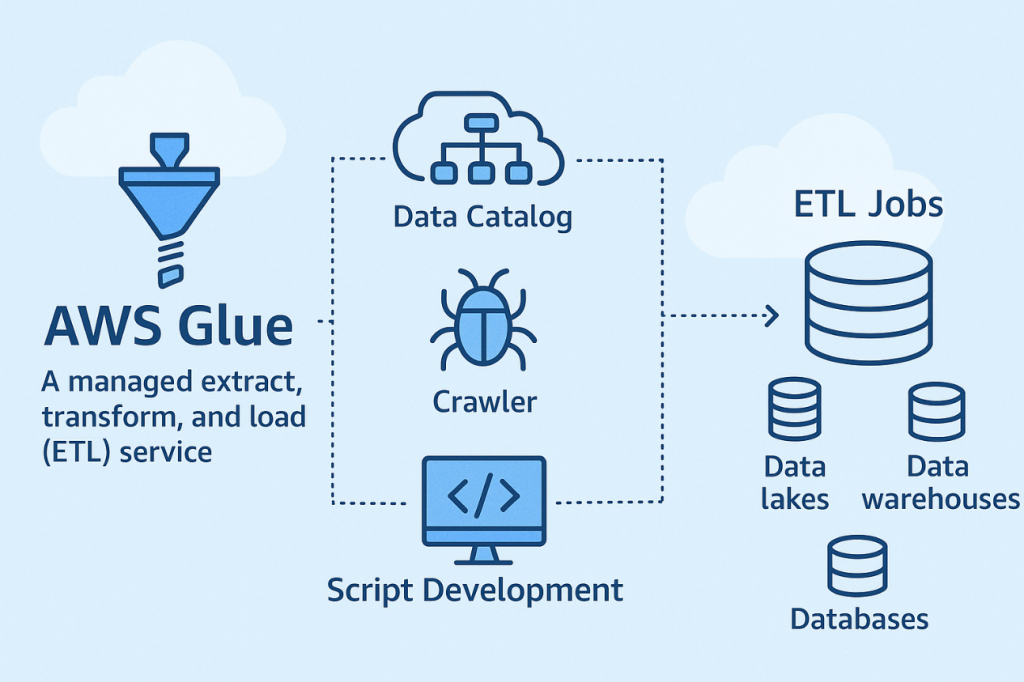
- What are the main components of AWS Glue?
Here are the main components of AWS Glue:
- Data Catalog – Central repository that stores metadata about data assets.
- Crawlers – Automatically scan data sources, infer schemas, and update the Data Catalog.
- Jobs – Run ETL scripts to clean, transform, and load data.
- Triggers – Automate the scheduling or execution of jobs.
- Development Endpoints & Workflows – Support testing and orchestration of complex pipelines.
- Glue Studio – Recently expanded with a drag-and-drop visual interface to simplify ETL development.
- What kinds of data sources can AWS Glue connect to?
Glue works with Amazon S3, Amazon RDS, DynamoDB, Redshift, and JDBC-based databases. It also supports data formats like JSON, CSV, Parquet, ORC, Avro, and modern lakehouse formats such as Apache Iceberg and Hudi via connectors.
- What is the AWS Glue Data Catalog?
The Data Catalog is a central repository that holds metadata about data assets. It allows services like Athena and Redshift Spectrum to query data easily using schema information.
- What is a crawler in AWS Glue?
A crawler scans data sources, identifies schema, and updates the AWS Glue Data Catalog with metadata tables. It can be scheduled to run automatically, keeping catalogs current as new or modified data arrives.
- What languages can you use to write AWS Glue ETL scripts?
AWS Glue ETL scripts can be written in Python or Scala. Both run on Apache Spark, allowing distributed data processing and transformations across large datasets with flexibility for developers.
- What is a Glue job trigger?
A Glue job trigger defines when ETL jobs start. It can be time-based, event-based, or on-demand, enabling automation of data pipelines. For example, triggering a job when a new file is uploaded to S3.
AWS Glue Interview Questions For Experienced
Let’s go through important AWS Glue interview questions and answers for experienced professionals that cover advanced concepts.
- How does AWS Glue handle schema evolution?
AWS Glue automatically detects schema changes using crawlers. If a new column or field appears, the crawler updates the Data Catalog. ETL jobs then adapt to the updated schema without breaking existing workflows. For stricter scenarios, developers can use the Schema Registry to version and validate changes before applying them, which avoids downstream failures. This is especially important when working with Iceberg or Hudi, which support schema evolution natively.
- What are DynamicFrames, and how are they different from DataFrames?
DynamicFrames are Glue’s abstraction designed for ETL. Unlike Spark DataFrames, they don’t require a fixed schema and can handle evolving or inconsistent data easily. They also provide built-in methods for cleaning and transforming semi-structured data like JSON. If you need performance-heavy operations, you can convert a DynamicFrame to a DataFrame and back again, combining flexibility with efficiency.
- How do you optimize AWS Glue ETL job performance?
Here are the tips to optimize AWS Glue ETL job performance:
- Use efficient file formats such as Parquet, ORC, or Iceberg/Hudi for reduced data scans.
- Push filters down to the source using pushdown predicates.
- Partition your data correctly to avoid full dataset scans.
- Scale the number of DPUs based on workload, but test to avoid over-allocation.
- Minimize shuffles in Spark jobs, as they often cause bottlenecks.
- What is a Glue Workflow and why is it useful?
A Glue Workflow allows you to combine jobs, crawlers, and triggers into a directed sequence. This provides orchestration for ETL pipelines. For complex workflows, many organizations now combine Glue Workflows with AWS Step Functions for advanced orchestration, retries, and error handling. This hybrid approach gives more flexibility than Glue Workflows alone.
- How does AWS Glue integrate with Amazon Redshift?
Glue can read from and write to Amazon Redshift tables. It supports both batch and incremental data loads. The Data Catalog acts as an external schema, enabling Redshift Spectrum to query S3 data directly. This combination creates a cost-effective hybrid warehouse and data lake model.
- What are Glue ML Transforms?
Glue ML Transforms provide out-of-the-box machine learning capabilities. The most popular is FindMatches, which helps detect duplicates and related records. These transforms allow teams to improve data quality without building custom ML pipelines, saving development time.
AWS Glue Scenario Based Interview Questions
These are practical AWS Glue ETL interview questions that are commonly asked to test your problem-solving skills in handling data pipelines and ETL workflows.
- Your dataset changes frequently. How would you handle schema updates?
Schema updates can be managed by running crawlers with schema evolution enabled. For production workloads, the Glue Schema Registry is preferred since it validates schema compatibility and prevents downstream job failures. Testing schema changes in a staging environment before rollout is a best practice.
- You only want new records processed daily. What’s your solution?
This can be achieved using job bookmarks, which track previously processed data. To make the process more robust, data should also be partitioned by date in Amazon S3. Even if bookmarks fail, only the required partition is scanned, avoiding unnecessary costs.
- A Glue job is running slower than expected. How do you debug it?
The first step is to check CloudWatch logs for errors and execution details. Performance bottlenecks often occur due to inefficient joins, skewed partitions, or unoptimized file formats. Converting data to Parquet or ORC, reducing shuffles, and tuning the number of DPUs are common fixes.
- You need to connect Glue with on-premises databases. How would you approach this?
A secure JDBC connection is required, usually over a VPN or AWS Direct Connect. Glue should be configured to run inside a VPC with endpoints to avoid public internet exposure. Proper IAM roles and secrets management are critical for security.
- You have multiple dependent ETL jobs. How do you manage them?
Glue Workflows provide orchestration by chaining jobs, crawlers, and triggers. Event-based triggers can be configured so that the completion of one job starts the next. Conditional branches and failure notifications add reliability to the pipeline.
AWS Glue MCQS
Here are some quick AWS Glue multiple choice questions to test your knowledge and preparation.
- Which AWS service uses the Glue Data Catalog for querying data stored in S3?
A) Amazon Athena
B) Amazon EC2
C) Amazon SNS
D) Amazon ELB
Answer: A) Amazon Athena
- What is the purpose of a Glue job bookmark?
A) To retry failed jobs
B) To track processed data so it doesn’t run again
C) To schedule jobs
D) To encrypt data
Answer: B) To track processed data so it doesn’t run again
- Which of these is not a supported trigger type in AWS Glue?
A) Time-based (cron)
B) Event-based
C) On-demand
D) Dependency-based (on file arrival)
Answer: D) Dependency-based (on file arrival)
- Which abstraction lets Glue handle evolving schemas more flexibly than Spark DataFrame?
A) RDD
B) DynamicFrame
C) Dataset
D) Table
Answer: B) DynamicFrame
- If you want to reduce data scan in a Glue job, which method helps?
A) Full table scan
B) No partitioning
C) Partition pruning / pushdown predicates
D) Increasing DPU
Answer: C) Partition pruning / pushdown predicates
- Which format is most efficient for Glue ETL to read/write large datasets?
A) CSV
B) JSON
C) Parquet
D) XML
Answer: C) Parquet
- When integrating Glue with a database (on-prem or external), which connector type is commonly used?
A) FTP
B) JDBC
C) SMTP
D) SSH
Answer: B) JDBC
Tips to prepare for AWS Glue Interview
AWS Glue interviews test both technical depth and problem solving in real-world data scenarios. Here are some tips to help you prepare:
- Learn AWS Glue basics like Data Catalog, Crawlers, and ETL jobs.
- Practice writing ETL scripts in Python or Scala.
- Revise schema evolution and partitioning concepts.
- Study common integrations with Redshift, Athena, and S3.
- Solve scenario-based problems with performance tuning.
- Review CloudWatch logging and cost optimization practices.
Wrapping Up
These 20+ AWS Glue interview questions and answers cover key topics to help you get ready for real interview situations. From basic concepts to advanced scenarios, the questions reflect what companies ask today. Keep practicing and building hands-on skills.
For IT opportunities, including AWS Glue job roles, check out Hirist – a trusted platform for tech jobs.
FAQs
They can be challenging for beginners since AWS Glue covers many concepts like ETL, schema evolution, and integrations. However, with practice on real projects and a clear understanding of fundamentals, most candidates can handle them well.
Companies like Amazon, Accenture, Deloitte, Infosys, Cognizant, and Capgemini frequently hire AWS Glue engineers. Many startups and cloud-first companies also look for Glue skills for data integration projects.
The process usually includes:
A technical screening (ETL basics, SQL, AWS fundamentals).
A coding round (Python or Scala for Glue jobs).
Scenario-based discussions on workflows, schema handling, and optimization.
Final round with hiring managers on projects and problem-solving skills.
Yes. Basic coding in Python or Scala is expected, as Glue jobs often require custom scripts. Even though Glue Studio offers a no-code interface, companies test candidates on scripting ability.
Candidates should revise SQL, AWS services like Redshift and Athena, CloudWatch monitoring, and data modeling. Knowledge of data lakes and streaming (Kinesis/Kafka) is also valuable.

{kind=link}